Dynamically Producing a Static Website
by Andrew Lamzed-Short at 15:15 in Website, AWS, Microsoft
Introduction
A fundamental component of a successful business is a modern, informative, and up-to-date website. It's a vital point of reference to convey what your business does, what sets you apart from the rest of the competition, how you can add value to customers by explaining the services and solutions you can provide for them, and various modes of contact.
At Lorax Compliance, we decided to bring our website into the fore, and to do this meant designing a system to automatically update our website in response to changes in the content, such as new blog posts and webinars. Being as committed to the technology behind our services as we are to the services themselves, we aimed to do this in a responsive, serverless manner. A pretty face belying hidden complexity.
Dynamic content, such as news and blog posts, provide vital information to others and highlight a company's expertise and expediency to keep abreast of their field of speciality, so it's important that a website can react to these changes to get these updates out as fast as possible. This is in addition to keeping static content such as portfolios, product descriptions, and company information up-to-date as well.
The downside to such responsiveness with current approaches is increased page bloat in the form of copious CSS and JavaScript libraries required for data retrieval and subsequent, asynchronous page rendering, drastically inflating the size of the webpages delivered to your browser. Not all browsers are up-to-date or desktop-class, so ideally it should load as fast as possible on all browsers to increase the likelihood of a visitor staying and reading the page. Using static pages is fine for a lot of purposes, but this also has two significant costs associated with it: manual editing and a lot of code duplication for common page elements such as navigation bars, footers, and other features. If a change needs to be made to one of these components, it must be performed multiple times across all files, leading to inevitable inconsistencies or breakages.
Our solution was to develop a system to split pages into templates and components. Each page and type of page would have its own template file – one for the about page, another for a blog post, for example. Into these, we replace the placeholders (the components and content) required to build the page in its entirety. Any updates to these template or component files, or any content, can be monitored and detected by several systems, and a website rebuild can occur, wherein the individual page and any dependent pages can be rebuilt and immediately published. For example, when a new blog post gets created, the departmental, tag, and overall blog pages must be updated also.
Architecture
Overview
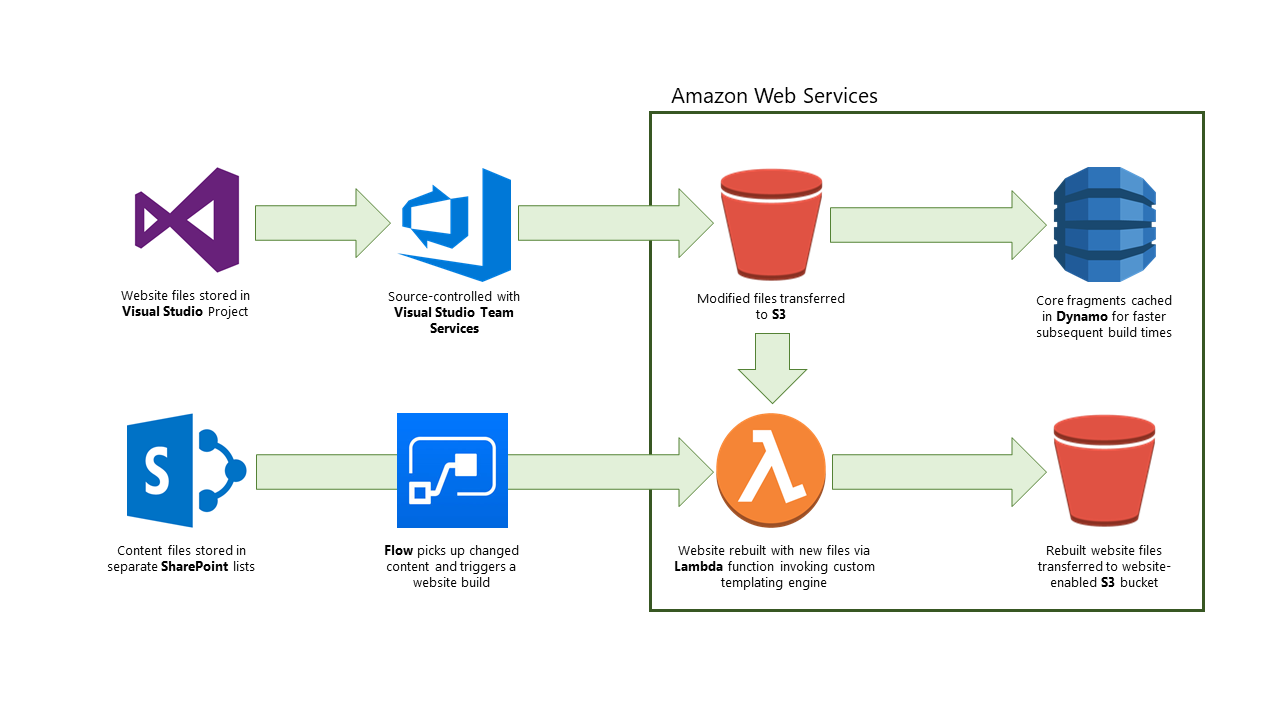

In the above picture, you can see at a glance how our website-building system is architected. The system is divided into two halves: the left half being the data-centric side of the system, the right side being the store and computational side.
Visually, you can see that the left-hand side forms two channels. The top-most channel is focused on the base website files themselves – the template pages and the components and fragments that are inserted into the templates. All these files are stored in an empty project in Visual Studio to leverage the immense power of the IDE with its syntax highlighting and aids to programming, which connects nicely into our source-control system of Visual Studio Team Services where we can version each of these files and keep track of the work accordingly.
The bottom-most channel is more content-focused. There are three main types of content we provide on our website at the moment: blog posts on recent developments in the world environment, plastics, recycling schemes, and surrounding legislature; news items highlighting the work Lorax is doing; and a list of webinars where we run various talks and workshops around new schemes and directive updates, to name a few.
Website Files
The folder structure of our website follows a standard static website template, with the blogs/ and webinars/ folders instead housing template files for their respective types of content. Webinars require different views depending on if a webinar is in the future or the past, so there are special case templates in these folders too, with the logic in our templating engine to determine which to use.
A full breakdown follows:
| blogs/ | Templates for blog posts and overall pages |
| css/ | External and bespoke styles |
| fonts/ | Custom fonts and modern typefaces |
| html/ | General fragments – header, analytics, footer, etc. |
| images/ | (Self-explanatory) |
| js/ | External libraries, components and bespoke scripts |
| webinars/ | Webinar page templates |
| index.html | Main entry point – templated out to use fragments |
| … | Rest of the main pages, favicon, misc. files |
The S3 bucket that stores these files has a structure that mirrors the one above so that developers know where to correctly store the files.
Templates
We divided the pages on our site into two categories: specific templates and specialised templates. Specific templates are for pages such as the index, about us, and contact pages that very infrequently change, and are for specific, unchanging content. Specialised templates are for items such as blog posts and webinar page that we would dynamically insert data into to populate the page for addition to the website. Data for the specialised pages is scraped from our SharePoint website as that is the content management system we use internally to store documents, image libraries, and additional content (more on this later).
You can imagine templates as a 'hollowed out' web page with common components stripped out to just leave the skeleton HTML tags and the page-specific content and formatting in-place. Fragments are brought in via a custom tag in a specified location in the template. This custom tag defines the fragment file name and additional dictionaries for custom overrides/replacements to tweak the fragment for the page.
The aim is to download the template as needed, replace the markers with the fragment code and adjust as defined, insert the data needed to complete the page, and push to result to the website.
Components and Fragments
Central to the deduplication problem is that of extracting HTML code that is required across multiple pages with little or no modification. Wouldn't it be nice to have a methodology to only have to perform one change once? Fragments are our answer to this and they are simply blocks of HTML code such as our navigation bar or analytics block. These files are dropped into one folder, all downloaded when the website or a certain webpage needs to be rebuilt, then the contents of which are simply copied into the locations where they are needed.
Content
As described earlier, the content that we present on our website consists of blog posts, webinar postings, and news items. Each of these is stored in a separate list in our SharePoint portal. Each list has common fields, such as Title, Author, Publication Date, and then specific fields, such as URL, Content, and Registration Link.
Our Compliance Team produce and source the content, and the appropriate Flows and SharePoint APIs grab the data and pipe it through to Lambda for processing. Very simple.
Process
In terms of how the file and content updates trigger a website rebuild, the process goes as follows:
File Update
- The developer working on a change to the website will upload the modified files to the associated staging/storage S3 bucket, in the same location as they're in under source control.
- The S3 bucket sends a notification/event to a watching Lambda function that monitors for changes to the content of the bucket.
- By examining the file type and location of the file specified in the S3 event, the Lambda function decides whether to delegate to the website building Lambda function (among other features and decisions it can make that will not be detailed in this post).
- If appropriate, it triggers the website building Lambda function with an event detailing the file to use.
- The website builder determines from the file if an individual or small group of pages needs to be rebuilt, or the entire website.
- Using Lorax's templating engine, the required templates and components to build the pages are loaded in from either S3 or Dynamo, and the final pages produced.
- Upon completion of templating, the files are saved to the target S3 bucket that hosts the website, and an invalidation request sent to CloudFront to invalidate the caches of the rebuilt pages to display the changes with near-immediate effect.
Content Update
- A member of Lorax staff adds or updates an entry to either the blog posts, webinars, or news items.
- A Flow in Microsoft Flow picks up this change and passes this information to a small Lambda function.
- Using the SharePoint APIs, the Lambda function gets the associated item from the ID it was given and serialises the details into an object the website builder can parse.
- The website builder takes this object and rebuilds the associated pages.
- Once rebuilt, the rebuilt pages are saved to the target S3 bucket that hosts the website, and an invalidation request sent to CloudFront to invalidate the caches of the rebuilt pages to display the changes with near-immediate effect.
Templating Engine
Having these templated-out files would be useless without an engine to do the loading, replacing, and formatting to tie everything together into the final product. We tried examining various solutions but found that none fit our needs. In fact, no solutions looked to statically do the templating, but rather most acted as middleware between the server and the client to pull in everything, build the page, and send the static HTML to the client. While similar, we wanted a system that produced the website pages one-time only, updating them as needed, so we would still technically have a static website, but one that was produced dynamically. Our reasoning behind this was it was easy to optimise, the pages didn't have dynamic or asynchronously loaded content, and we'd improve the response time because we'd only be serving a file, rather than doing superfluous calculations, loading, or rendering.
At a base level, the only components of our engine are the Lambda function, and the templating code itself. As the process of loading components and templates and the general templating procedure are common across all of the types of content, we adopted a software engineering approach called a 'factory pattern' where we move all common functionality into an abstract base class, and place the content-specific code into concrete implementations that inherit from (and override where necessary) the base class. The website builder simply determines what type of file it was provided was, and instantiates the correct class, calling the base class's methods, and letting the implementation do the trick. A UML class diagram is provided below.
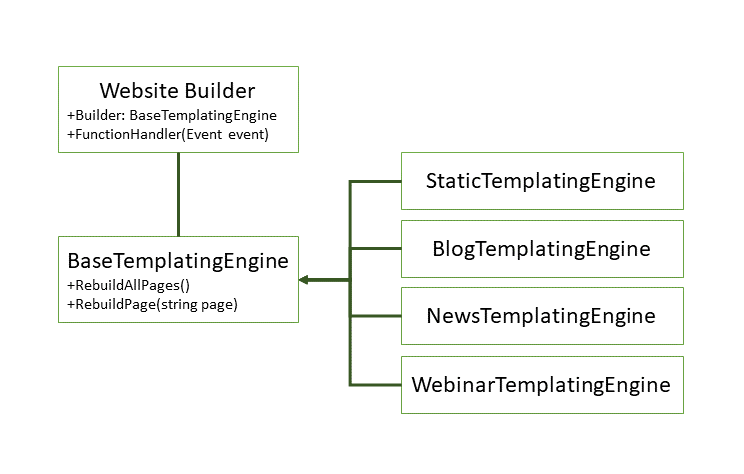

The templating engine was produced in a way that reduced cohesion between the engine itself and the Lambda function. What this means is that we give the engine all of the pre-loaded files when it's created and it produces the finished pages for us, it doesn't know anything about external AWS services, SharePoint, or the like. This enables us to potentially transfer this engine elsewhere, or even package it up as a .dll code library for future use or release.
Each implementation of BaseTemplatingEngine handles the specifics of each content type. Webinars, for example, rebuild the overall /webinars page when a new webinar gets added to update the list with a summary and link to the new page so users can find the page. The previously unmentioned 'StaticTemplatingEngine' handles the non-content-based pages, like the home page, /software, or /contact.
Conclusion
Overall, we would consider this experiment a success. Our website is updated in response to file and content updates only when and as necessary, updating only the pages required to reflect the changes and no others.
Deploying the solution was as simple as creating the lists in SharePoint and buckets in S3 and linking them together with Microsoft Flow and AWS Lambda. Should we need to update the code, we just redeploy the Lambda function and it's immediately ready to go.
The templating engine was also produced in such a way that the potential is there to create an open-source version of it for others to use, given that we previously could not find any other solution that filled in this niche.
We hope that you enjoy the new website!
Further Work
As a first attempt at such a system, we achieved exactly what we set out to do and have a dynamically built, always up-to-date website as a result. During the development of the system, certain ideas came to mind that would greatly improve the system either in its dynamism or reliability that weren't fundamental, so were left as future work. Here are a few ways we will improve the system in versions to follow.
Dependency Graphs
Creating an outline of all the fragments and templates used to build the website and creating a network/tree with links between files that depend on one another, such as /webinars being dependent on individual pages, and all pages depending on the 'header' fragment, would enable the code to automatically select the files it needs to rebuild when a given file in S3 is modified.
Auto-Copy Modified Files to S3
When the website project is 'built' in Visual Studio, or a .css file (for example) is checked-in to our source control system, it's easy to forget to update the file in S3 to trigger a website rebuild to utilise the modified file. It would be nice to have the option to have a system automatically detect this change, transfer the file, and trigger a rebuild automatically.
Approval-Based Process for Deployment to Live Website
It's easy to forget a file after the testing has been done for the test version of the website, resulting in the two websites becoming out of sync with one another. Eliminating this point of failure could be done by having a system that keeps track of files that have changed between test and live since the last update and just having 'Sync' or 'Update' button on an admin panel to trigger this update would greatly improve the updating experience.
Batched Updates
Dropping multiple files at once into an S3 bucket triggers many invocations of the Lambda functions at once, causing the function to be triggered multiple times for individual files rather than once for a group of files. Building a queue function into the system and a routine to digest and condense messages into groups to trigger a rebuild function once would save on unnecessary S3 interaction and Lambda calls, literally saving time and money.
